
教材の内容に関係のない質問や教材とは異なる環境・バージョンで進めている場合のエラーなど、教材に関係しない質問は推奨していないため回答できない場合がございます。
その場合、teratailなどの外部サイトを利用して質問することをおすすめします。教材の誤字脱字や追記・改善の要望は「文章の間違いや改善点の指摘」からお願いします。
 カテゴリー
カテゴリー
Pythonデータ分析の一連の流れ(データの取り込み、データクレンジング、集計、グラフ化、考察)を習得する。
このパートから、Google Colaboratory環境上で実際のKICKSTARTERのデータを活用して作業を行います。Google Colaboratoryの環境準備や、KaggleからのKickstarterのデータダウンロードは完了している前提で進めていきます。
まだ環境準備やKICKSTARTERのデータのダウンロードが完了していない方は、以下のパートを参考にしてください。
本パートでは、新規にGoogle Colaboratoryのファイルを作成し、KICKSTARTERのデータを取り込んで表示させるところまで進めます。
では実際に進めていきましょう。
まずはGoogle Colaboratoryにアクセスします。ファイルタブからPython3の新しいノートブックをクリックします。
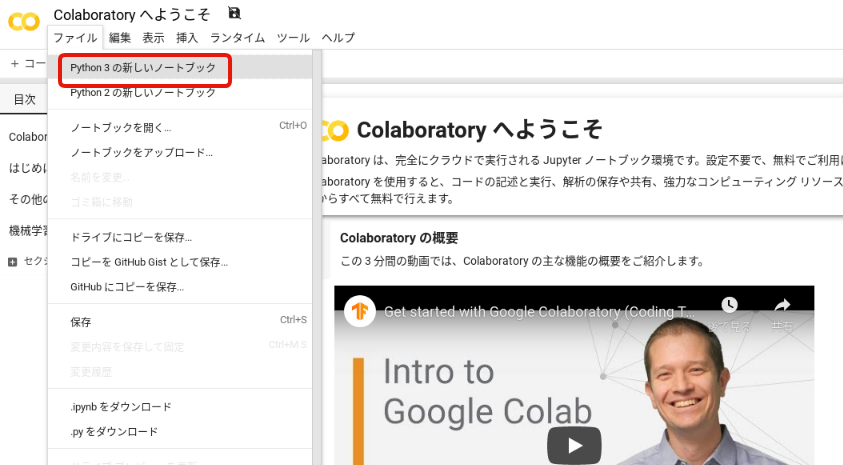
ファイルを新規作成すると下記画像のような画面が表示されます。ファイル名を名付けましょう。ファイル名は任意ですが、本教材ではanalytics_01.ipynbとします。拡張子は必ず.ipynbとしてください。
データ分析に必要なライブラリのインポートを行います。Pythonでは、importコマンドによって必要なライブラリを取り込みます。Google Colaboratoryを起動して下記コマンドを実行(Shift + Enter)してみましょう。
py1234567 Copied!import os
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
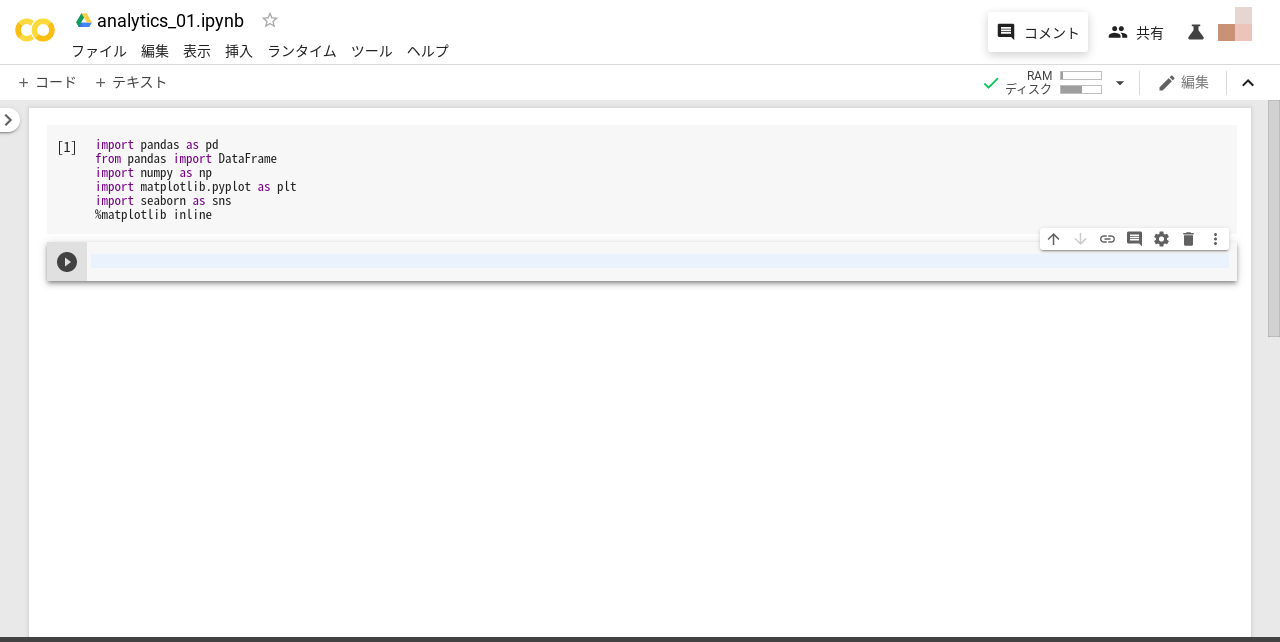
問題なくインポートが完了したら次のセルがアクティブになります。各インポートコマンドについて、簡単に解説します。
import osOSライブラリをインポートするコマンドです。OSライブラリは、OSに依存しているさまざまな機能を提供しています。主にファイルやディレクトリ操作が可能です。例えば、ファイルの一覧やファイルパスの取得、新規ファイル・ディレクトリの作成が可能です。後ほど説明しますが、本教材では、データセットの保存先ファイルパスを取得する際に、OSライブラリを活用します。
import pandas as pdPandasライブラリをインポートするコマンドです。Pandasライブラリは、データ分析に関する様々な機能を提供します。例えば、データの読み込みや欠損値の補完、正規化、統計量の表示、グラフ化が可能です。
as pdはインポートしたPandasをpdと名付ける命令文です。これによってPandasのメソッドを利用する際にpandas.メソッド名とタイピングが必要なところをpd.メソッド名とタイピングするだけで利用可能となります。
from pandas import DataFramePandasライブラリの一部であるDataFrameライブラリを個別でインポートするコマンドです。ライブラリの中でも使用頻度が高い部分のみ取得したい場合にfromを利用して個別インポートが可能です。DataFrameのメソッドを利用する際にpd.DataFrameとタイピングが必要なところをDataFrameとタイピングするだけで利用可能となります。
import numpy as npNumpyライブラリをインポートするコマンドです。Numpyは数学的な機能を提供します。データ分析によって、複雑な計算が求められるケースがあります。Numpyを利用すると複雑な計算処理を、シンプルなメソッドで実行できます。
import matplotlib.pyplot as pltMatplotlibライブラリの中のpyplotをインポートするコマンドです。Matplotlibはグラフ作成の機能を提供し、特にPyplotはグラフを出力するメソッドを持ちます。
import seaborn as snsSeabornライブラリをインポートするコマンドです。Seabornもグラフ作成用のライブラリです。Matplotlibよりも、簡単にかっこよくグラフ生成できるという特徴があります。Matplotlibはカスタマイズ性が高く、Seabornは手軽に作成できるという点が、それぞれのメリットです。
%matplotlib inlineグラフ描画した画像をGoogle Colaboratory内に表示させるためのコマンドです。このコマンドだけライブラリのインポートの処理ではありません。MatplotlibやSeabornでグラフを作成する場合、画像ファイルは指定したフォルダに保管されます。%matplotlib inlineを実行することで、Google Colaboratory内に表示させることが可能です。
いずれのライブラリでも、非常に多くの機能を持ちます。すべてを一度に把握するのは難しく、現段階では、このような機能があるのだなあという程度の理解で構いません。
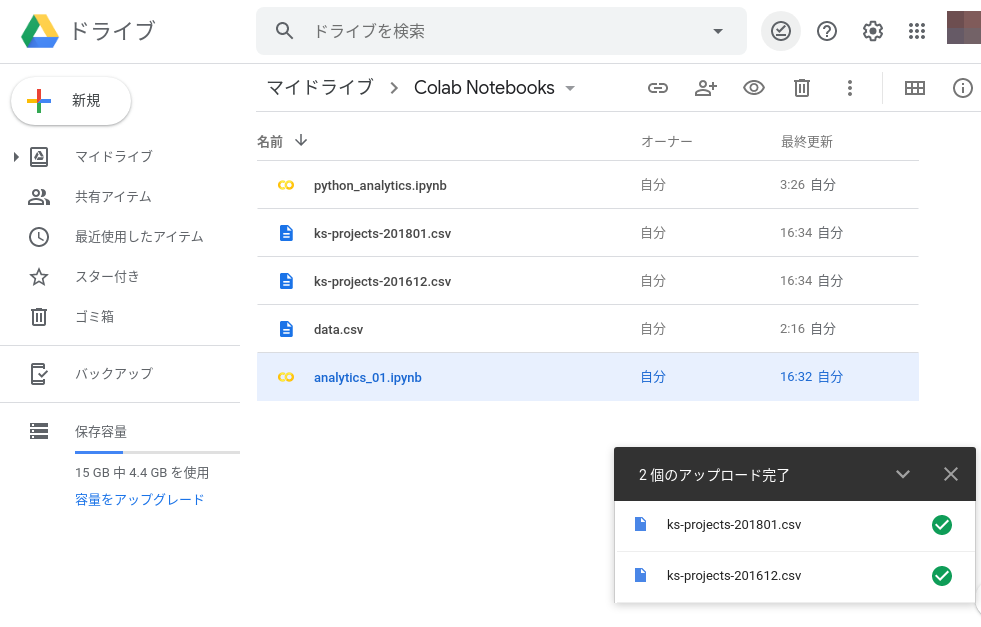
データセットであるks-projects-201801.csvとks-projects-201612.csvをGoogleドライブへ保管します。ks-projects-201801.csvとks-projects-201612.csvをGoogleドライブのColab Notebooksフォルダ内にドラッグアンドドロップするだけで保存できます。下記画像のように表示されれば成功です。
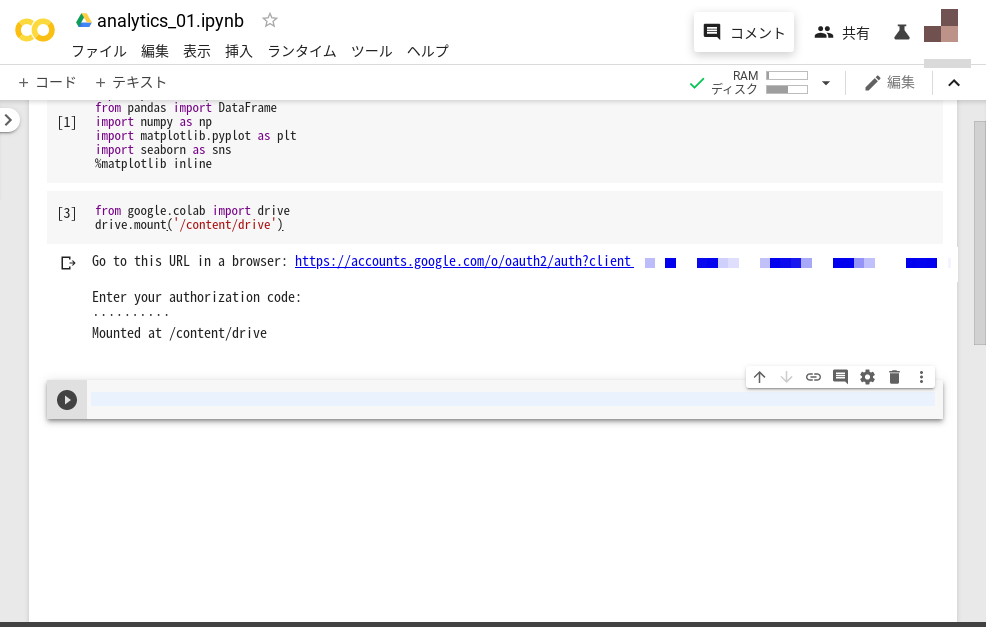
次にGoogle ColaboratoryとGoogleドライブを連携させます。Google Colaboratoryから下記コマンドを実行してください。出力されたリンク先のパスワードをEnter your authorization code:の下に貼り付けて実行しましょう。
py12 Copied!from google.colab import drive
drive.mount('/content/drive')
下記画像のようにMounted at /content/driveと表示されれば、問題なくGoogle ColaboratoryとGoogleドライブの連携が完了しています。
次にGoogleドライブに保存したデータファイルの保存先のパスを指定します。パスの指定はOSライブラリのchdirメソッドを利用します。os.chdir('/ディレクトリまでのファイルパス')でパスを指定できます。今回のデータ保存先は/content/drive/My Drive/Colab Notebooksです。下記コードを実行します。
py1 Copied!os.chdir('/content/drive/My Drive/Colab Notebooks')
特に何も表示されませんが、問題なくパスの指定は完了しています。
次にGoogleドライブに保存したデータをGoogle Colaboratoryに取り込みます。Pandasライブラリのread_csvメソッドを利用して、CSVファイルを取り込みます。
py1 Copied!df = pd.read_csv('CSVファイル名', header = None)
今回はCSVファイル名がks-projects-201801.csvで、CSVファイルの1行目をカラム名として挿入します。
下記コマンドを実行します。dfはDataframeの略で、データセットを格納する変数名としてよく利用されます。
py1 Copied!df = pd.read_csv('ks-projects-201801.csv')
dfにデータが格納されていること確認してみましょう。下記コマンドを実行します。
py1 Copied!df
下記動画のように出力されます。
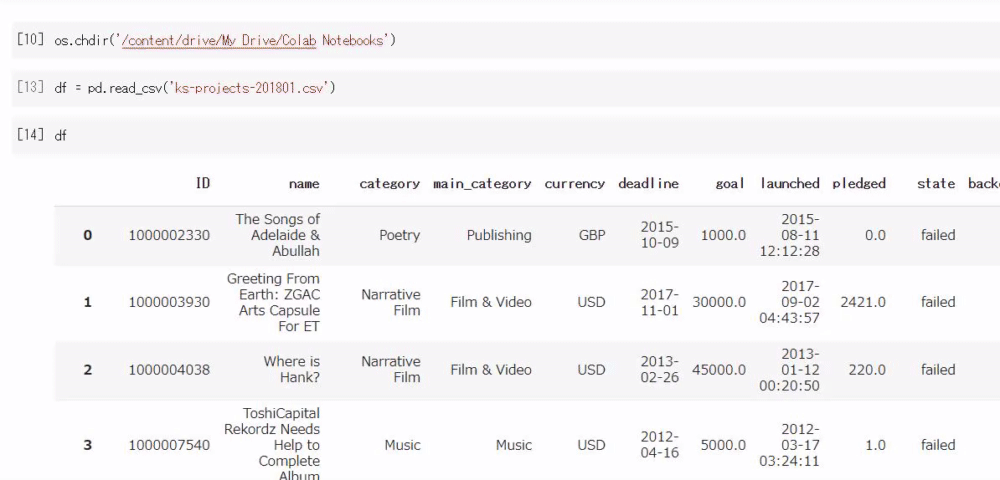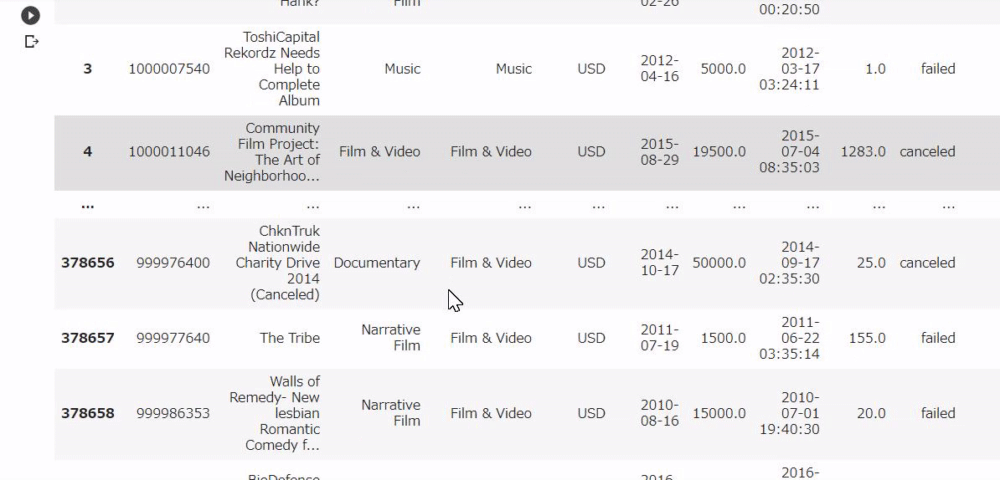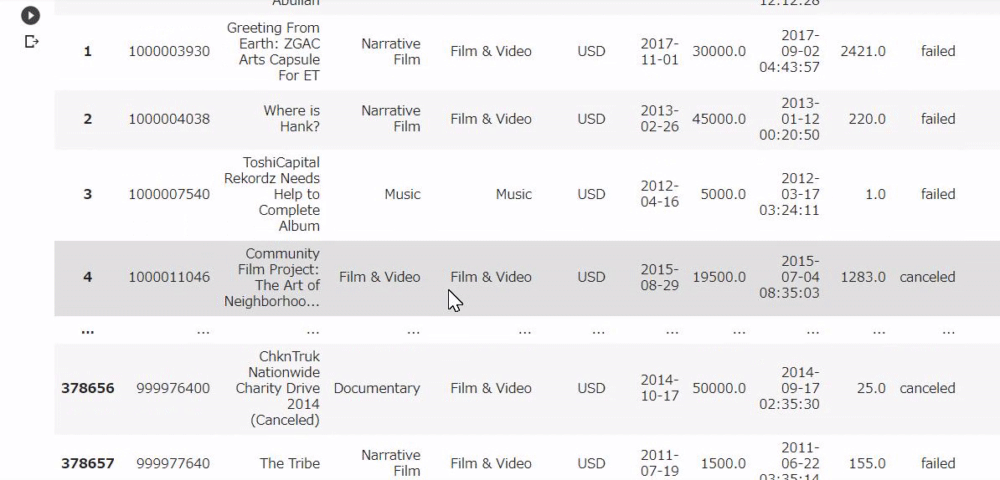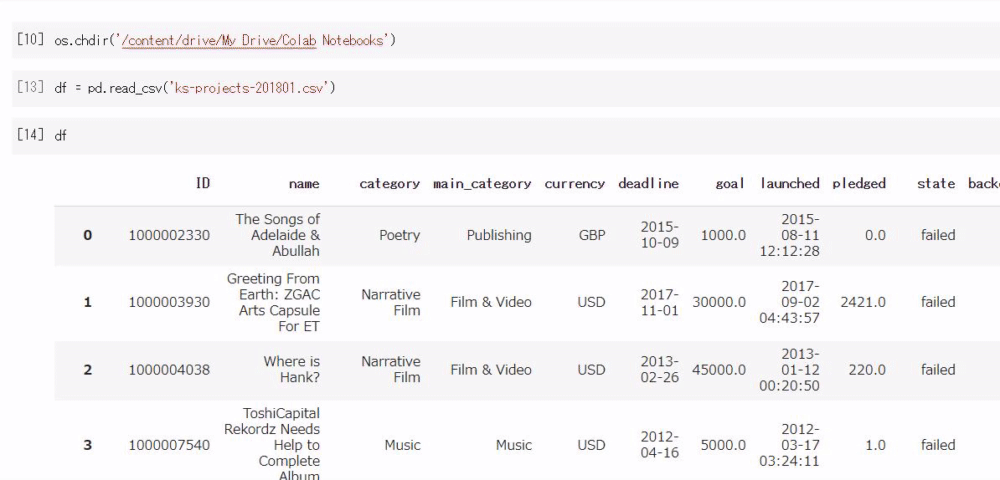
データソースファイルのデータと同じであることが確認できます。
データが大規模の場合は、一般的に上から数行のデータのみ出力させてデータ確認します。例えば、上から5行分だけ表示させたいときは下記コマンドを実行します。
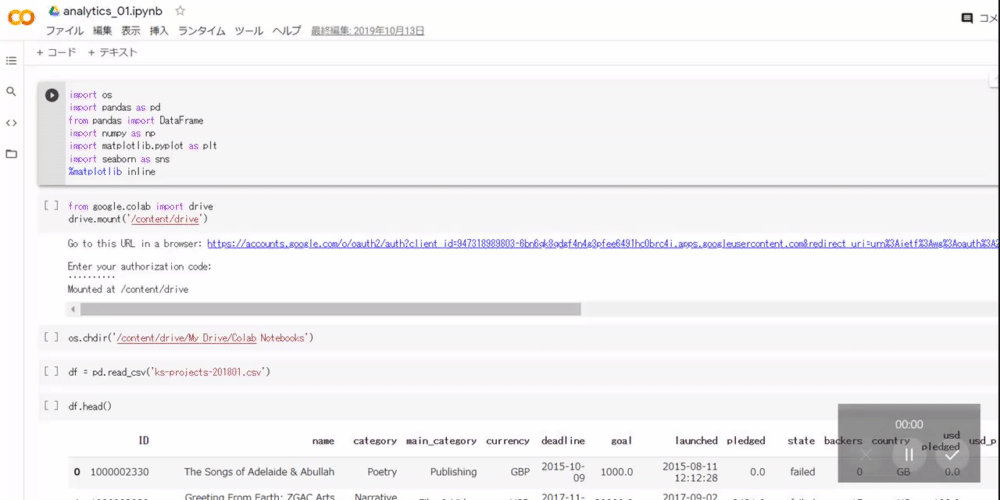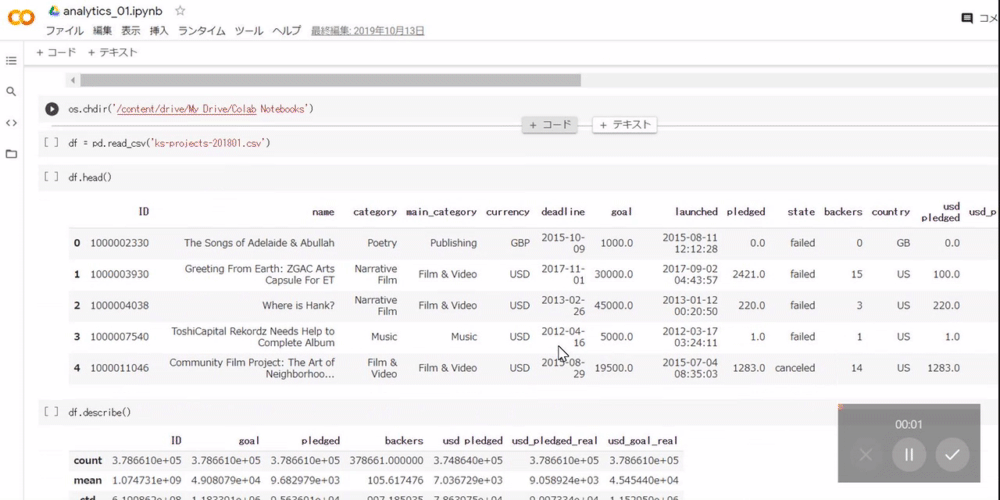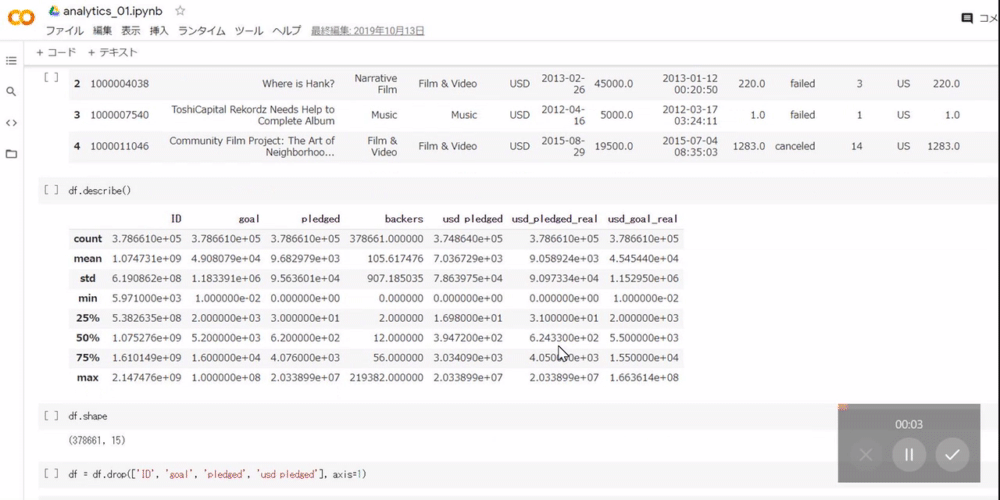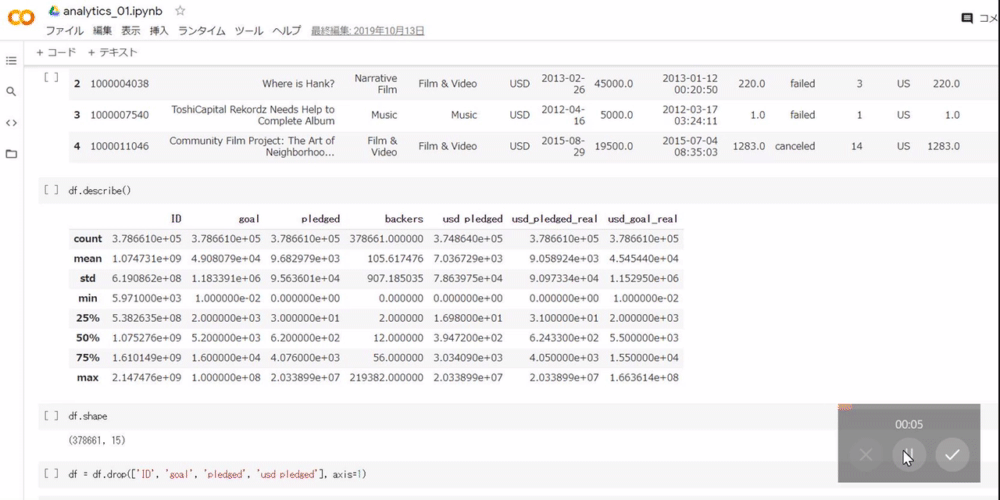
py1 Copied!df.head()
下記画像のように出力されます。
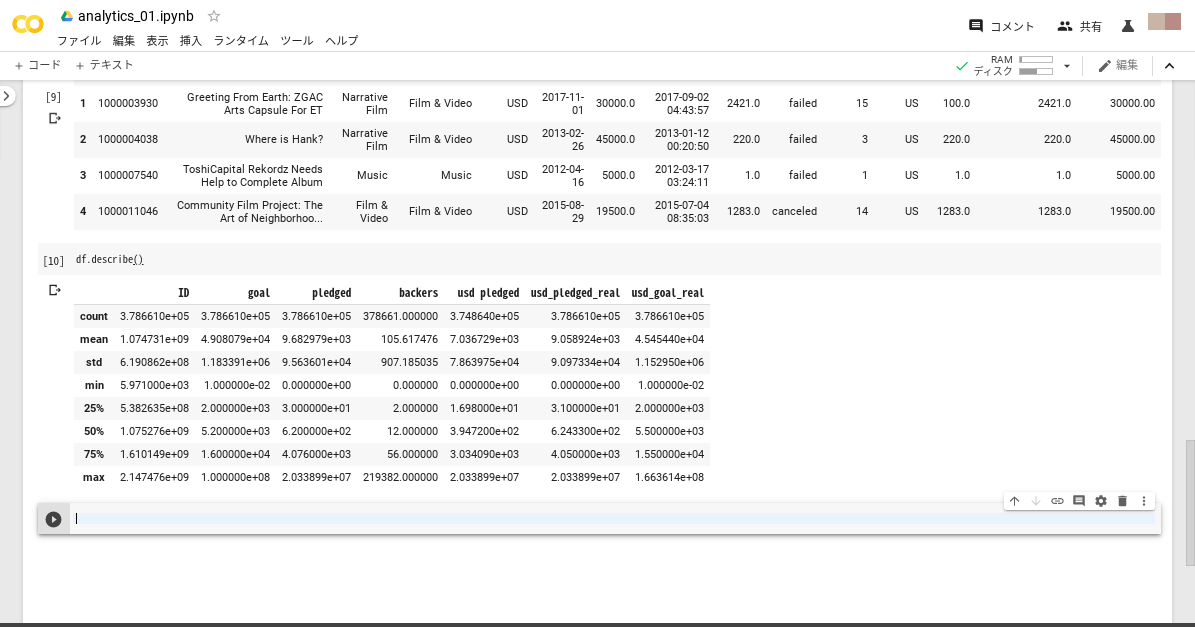
各列のデータ数や平均、標準偏差、最小値、中央値、最高値などを確認したい場合は、下記コマンドを実行します。
py1 Copied!df.describe()
下記画像のように出力されます。
出力された文字について簡単に解説します。
count:データ数mean:平均値std:標準偏差min:最小値25%:データを小さい順に並べ、25%の位置にある値(第1四分位数と呼ばれます)50%:データを小さい順に並べ、50%の位置にある値(中央値と呼ばれます)75%:データを小さい順に並べ、75%の位置にある値(第3四分位数と呼ばれます)max:その列の最大値※e+nは、10のn乗を意味します。例えば3.786610e+05は378661のことです。
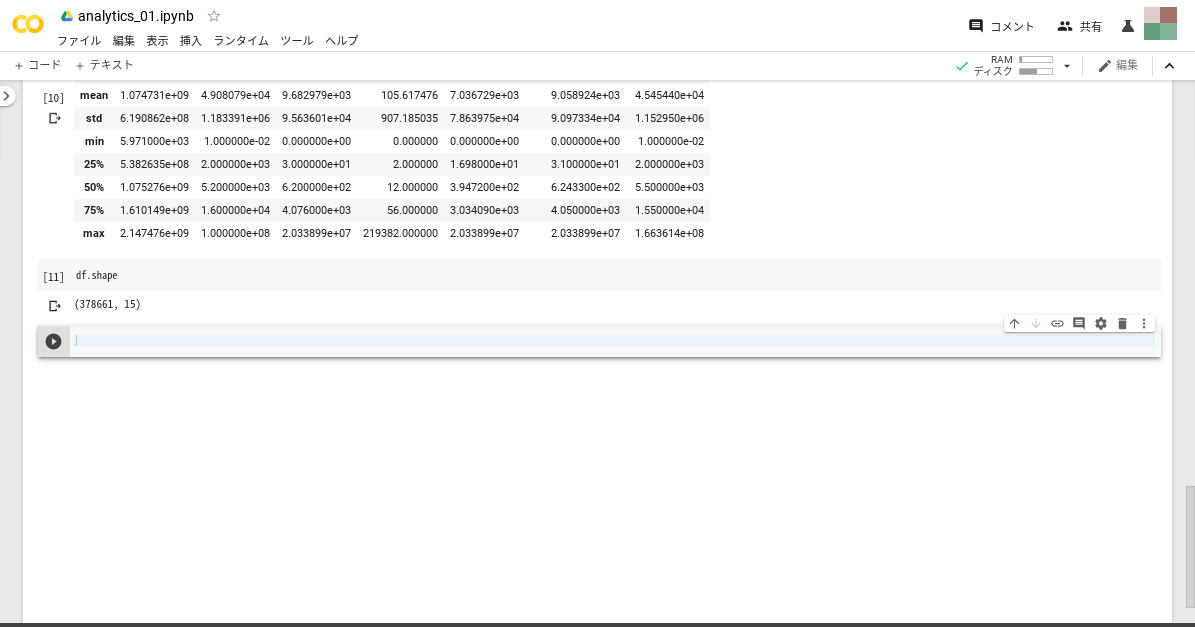
データの行と列のサイズを見たい場合は下記コマンドを実行します。
py1 Copied!df.shape
下記画像のように(378661, 15)と出力されます。列名や行番号を除いて、dfが376881行×15列のデータであることを意味しています。
本パートではCSVファイルを取り込みましたが、Excelファイルや、WEBサイトなどからコピー&ペーストしたデータなどの取り込み方法も解説します。教材の本筋からはズレますが、ぜひ試してみましょう。Excelファイルをデータソースとして取り込む場合は、以下のコマンドを実行します。
py1 Copied!df = pd.read_excel('Excelファイル名', sheetname='シート名', header = None)
データソースをコピー&ペーストによって取り込む場合は、コピーした状態で以下のコマンドを実行します。
py1 Copied!df = pd.read_clipboard(header = None)
以上で今回のパートは終了です。次のパートではデータ分析の事前処理として必須である「データクレンジング」を行っていきます。

